
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- time slice
- spring
- Hot Publish
- RxJava
- OS
- 생활코딩
- spring boot
- 병렬 피처 개발
- oh-my-claudecode
- 버전관리
- Git
- CLI
- js
- CPU Scheduling
- Depromeet
- 건국대학교
- AI parallel develop
- Round Robin
- Cold Publisher
- claude code
- 원격 저장소
- js 개발자라면 알아야하는 핵심 컨셉
- 큐시즘
- 자바스크립트
- github
- Hot Publisher
- 파이썬
- OOAD
- Observable
- 마블 다이어그램
- Today
- Total
글쓰는 개발자
[Web Crawling]다음 주식정보 Crawling하기 with Python 본문
요즈음 파이썬을 이용해서 크롤링을 공부하고 있다. 공부한 지 한 1~2달 정도 된 것 같다.
크롤링을 공부하는 과정에서 웹에서 정보를 어떤 식으로 주고받는지 조금씩 알아가고 있는 중이라 뿌듯하다.
공부한 것들을 정리할 겸, 또 누군가에게 도움이 될 수도 있지 않을까 하여 그 과정을 초보자의 입장에서 풀어써보려 한다.
[개발환경]
언어 : python 3.5.2
OS : Ubuntu 16.04
오늘은 공부하는 과정에서 조금 난관을 겪었지만 배운 점이 많았던 다음 주식정보 긁어오기다.
이게 내 입장에서 왜 어려웠냐면, 크롤링을 처음 배우는 단계에서는 그냥 터미널 환경에서 request를 날리고 response를
받아 BeautifulSoup 같은 라이브러리를 이용해서 잠깐 만지작대다 보면 쉽게 데이터를 가공할 수가 있었다.
예를 들어 https://finance.daum.net의 인기검색 종목을 가져오려는 경우에

이렇게 개발자모드로 분석하고 해당 엘리먼트에 접근해서
import requests
from bs4 import BeautifulSoup as bs
url = 'https://finance.daum.net'
response = requests.get(url)
bsObj = bs(response.content,'html.parser')
ranks = bsObj.findAll('ul',{'id':'boxTopSearchs'})
print(ranks) 이런식으로 코드를 써주면 80%는 해결이 되었다.
그러나 다음이나 네이버 같은 대형 사이트 또는 기본 구성이 잘 되어있는 사이트의 경우에, 어떤 것을 크롤링하느냐에 따라서
단순히 request만 날렸다간 정작 필요한 데이터는 하나도 받지 못하고 사이트의 구조만 날아오는 당황스러운 상황이 생길 때가 있다. 바로 이렇게.

우와.. 처음에 이런 상황에 직면했을 때 굉장히 황당했다. 웹 관련 지식도 전무해서 이게 왜 이러는건가 한참을 생각해도 답이 나오질 않았다.
며칠간 구글과 생활코딩을 헤집고 다닌 뒤에야 이것이 Ajax를 통해 비동기적으로 데이터를 불러온다는 것을 알게 되었다. (아! 이게 말로만 듣던 Ajax구나! 싶었다. 어느 정도 실력이 쌓이면 Ajax를 공부해봐야겠다.)
아무튼, '이게 왜 이러나'하는 상태에서 'Ajax를 통해 비동기적으로 데이터를 불러오는구나'하는 상태로의 발전이 있었으니, 다음 차례는 '비동기 처리 데이터는 어떻게 가져오는가'였다.
또 열심히 구글링하고 내 나름대로의 방법을 찾아본 결과, 두 가지 방식으로 좁혀졌다.
첫 번째는 Selenium을 이용해 headless browser로 접근하여 동적 데이터를 로드시켜 가져오는 것이었고,
두 번째 방법은 직접 필요 데이터에 접근하여 정적인 데이터를 가져오는 것이었다.
사실 Selenium을 썼으면 문제가 훨씬 빠르고 쉽게 해결되었을 텐데, 내 신분상(군인..) 최대한 패키지 설치는 피해야 하는 상황이었다. (Codeanywhere가 HDD가 2GB밖에 지원 안된다.. 용량 늘리는 건 비쌌다..)
Selenium을 쓰지 못하니 이젠 끝인가.. 하던 와중에 개발자 모드의 Network 탭을 관찰하다가 해결책을 찾게 되었다.
개발자 모드에 들어가서 아래 사진처럼 Network 탭의 XHR 필터를 적용해주고 새로고침 해주면,

이렇게 로드되는 XHR 파일들이 보인다. 그중에 ranks?limit=10 파일을 눌려서 preview 탭을 살펴보면,
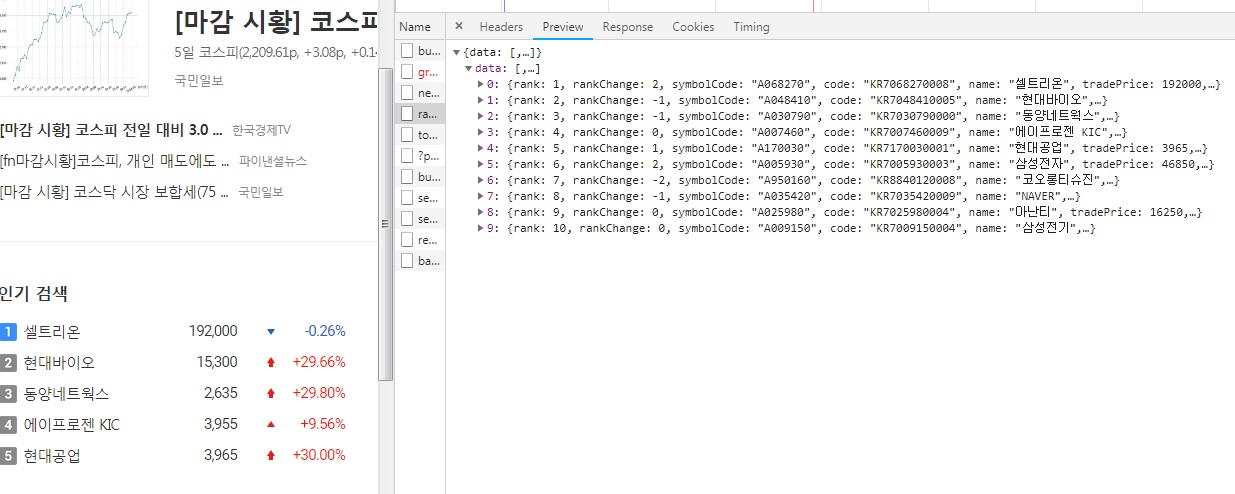
왼쪽 인기 검색 데이터를 오른쪽 개발자 모드에서 그대로 볼 수 있는 것이 확인된다. 대박! 이걸 찾았을 때 되겠구나 싶었다.
다시 headers 탭을 눌려 request url을 살펴보면,

친절하게 url 주소가 적혀있다.
그럼 이 주소를 대상으로 다시 크롤링을 시도해보면 되겠다.
import requests
from bs4 import BeautifulSoup as bs
url = 'https://finance.daum.net/api/search/ranks?limit=10'
response = requests.get(url)
print(response)
위 코드를 실행시키면!

403 Forbidden error를 반환한다. 참 난관이 많다.
403 error 같은 경우에 발생 원인이 여러 가지다. 접근 권한이 없을 때도 있고, 또 다른 이유일 수도 있다.
왜 이러나 찾아보았더니, Request를 보낼 때 헤더 정보가 부족해서 그렇단다.
다시 한번 개발자 모드를 켜서 해당 파일 request 헤더를 살펴보아야겠다.
(참고로 request 헤더는 앞의 preview 탭 바로 옆에 있습니다.)

이것은 정상적으로 데이터를 받아 왔을 때, 다시 말해 다음 사이트에서 ajax를 통해 데이터를 가져왔을때의 헤더정보이다.
그리고 파일의 url에 직접 접근했을 때의 헤더는(url을 주소창에 입력해서 Network 탭을 살펴보면 나온다.)

이러하다.
꼼꼼히 살펴보면 뭔가 좀 생긴 게 다르다. 오호?
그럼 성공했을 때의 request header와 실패했을 때의 request header의 차이를 살펴보면,
어떤 것을 추가해줘야 하는지 알 수 있겠다.(사실 그냥 로드에 성공한 파일의 request header를 통째로 ctrl+c ctrl+v 해도 된다.)
이 경우에는 첫 번째 request header의 user-agent와 referer를 추가해주니 정상 작동되었다.
import requests
from bs4 import BeautifulSoup as bs
url = 'https://finance.daum.net/api/search/ranks?limit=10'
response = requests.get(url)
print('1 :',response)
headers = {
'Referer': 'http://finance.daum.net',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36 OPR/58.0.3135.127'
}
response = requests.get(url, headers=headers)
print('2 :',response)
위 코드를 실행시켜보자.

성공! header를 추가한 후에 200(정상 작동)을 반환하였으니, 데이터 접근이 가능하게 된 상태이다.
이제 정말 90%는 다 왔다.
XHR 데이터에 직접 접근하는 경우에는 JSON 형태로 데이터를 받아와야 한다.
이 데이터는 beautifulsoup를 이용해서 가공할 수 없기 때문에, 파이썬 requests에서 지원하는 json 함수를 이용한다.
이제 데이터를 출력해보면,
import requests
from bs4 import BeautifulSoup as bs
url = 'https://finance.daum.net/api/search/ranks?limit=10'
headers = {
'Referer': 'http://finance.daum.net',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36 OPR/58.0.3135.127'
}
response = requests.get(url, headers=headers)
jsonObj = response.json()
print(jsonObj)

데이터가 dictionary 형태로 저장되었음을 볼 수가 있다.
이제 가공만 하면 된다!
제목만 한번 따와보도록 하자.
import requests
from bs4 import BeautifulSoup as bs
url = 'https://finance.daum.net/api/search/ranks?limit=10'
headers = {
'Referer': 'http://finance.daum.net',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36 OPR/58.0.3135.127'
}
response = requests.get(url, headers=headers)
jsonObjs = response.json()
dataList = jsonObjs['data']
for data in dataList :
print(data['name'])

드디어 제목을 뽑아냈다! 정말 내 나름대로는 험난한 여정이었다..
이로써 Ajax를 통해 비동기적으로 로드되는 데이터를 데이터에 직접 접근하여 가져와 보았다.
글 작성자처럼 특수한 상황에 처한 사람이 아니라면, 그냥 Selenium을 이용해서 크롤링할 것을 더 추천한다.
그건 beautifulsoup도 연계해서 쓸 수 있으니까..
아무튼 이렇게 시행착오를 겪는 과정에서 많은 부분들을 배우게 되었다.
배운 점들을 정리해보면,
- Ajax로 처리되는 데이터는 단순히 get 요청으로 불러올 수 없어서, Selenium을 이용하거나
XHR 데이터 url에 직접 접근하는 방법으로 크롤링하여야 한다. - XHR 데이터에 직접 접근하는 것을 막아놓는 경우가 있는데, 보통 헤더 정보가 없어서 그런 경우가 많다.
그런 경우에 헤더를 추가해주면 대부분 해결됨. - XHR에 직접 접근할 경우 JSON 데이터로 반환되기 때문에 json parsing을 해주어야 한다.
- 웬만하면 Selenium 쓰자..
이 정도가 되겠다.
크롤링을 하다 보면 다양한 변수들이 발생한다.
이번 경우처럼 접근이 막히는 경우도 있고, 로그인이 없이는 볼 수 없는 정보들도 있다.
이런 경우 하나하나에 대한 방법을 찾고, 해결함으로써 실력이 많이 느는 것 같다. 앞으로도 계속해서 도전해야지.
※참고 : 같은 사이트 내에서도 크롤링이 가능한 곳이 있고 가능하지 않은 곳이 존재하는데, 그것에 대해서는 나무 위키의 robots.txt를 참고하시길 바랍니다.
'Development > 기타' 카테고리의 다른 글
| [이론]js 개발자라면 알아야하는 핵심 컨셉 33개 #5.Typeof (0) | 2019.06.14 |
|---|---|
| [이론]js 개발자라면 알아야하는 핵심 컨셉 33개 #4.Type Coercion (0) | 2019.06.11 |
| [이론]js 개발자라면 알아야하는 핵심 컨셉 33개 #3.Value Types and Reference Types (0) | 2019.06.09 |
| [이론]js 개발자라면 알아야하는 핵심 컨셉 33개 #2.Primitive Types (0) | 2019.06.08 |
| [이론]js 개발자라면 알아야하는 핵심 컨셉 33개 #1.Call Stack (0) | 2019.06.06 |



